Jak dopadlo srovnání rychlostí PCIe pro AI?

Rozhodli jsme se srovnat výsledky AI benchmarků pro PCIe gen4 x16, PCIe gen4 x4 a PCIe gen3 x2, jelikož jsme zatím žádné takové srovnání nedohledali a může to být rozhodující při volbě HW pro AI. Nejbližší takové srovnání je pět let staré a porovnává jen PCIe x16 a x8. Od té doby však technologie pro AI nesmírně pokročily.
O srovnání
Výsledky a unikátní srovnání přináší náš člen deepit.cz. Jedná se o malou firmu zabývající se AI systémy na míru s vlastním hardwarem a heslem: „Když to umí GNN, nepoužívej LLM.“ Mnohokrát děkujeme za kompletní přípravu a sdílení výsledků.
PCIe slot je tvořen datovými linkami v různém počtu, kdy má každá různou datovou propustnost dle její generace, viz. Wikipedia. V tomto testu máme k dispozici na základní desce Gigabyte Aorus Master x670e tři různé PCIe sloty:
- Generace 4 s šestnácti linkami – teoretická propustnost 32GB/s.
- Generace 4 se čtyřmi linkami – teor. propustnost 8GB/s.
- Generace 3 se dvěmi linkami – teor. propustnost 2GB/s.
Cílem je odpovědět na otázku, zda a jak moc je rychlost tohoto slotu omezující pro AI výpočty. Ve starém testu viz výsledky výše vyšly téměř podobné – minimální rozdíl mezi x8 a x16 PCIe linkami.
Testovací sestava
- AMD Ryzen9 7950x3d, 16 jader (32 vláken), AiO Arctic Freezer II 420mm
- Gigabyte Aorus Master x670e
- Corsair Vengeance DDR5 192GB@5200MHz, 4x48GB kit
- 2x Kingston KC3000 1TB
- Asus Dual RTX 3060 12GB
- 12x Arctic P14
- Seasonic Vertex GX-1200 Gold

Testovací SW
- Windows 11
- nVidia driver 546.01
- UL Procyon
- 3DMark Advanced Edition
Benchmarky
- nVidia TensorRT test, 8.6.1.6
- Microsoft Windows ML, 1.15.1
- 3DMark PCI EXPRESS
- 3DMark Time Spy
Testovací postup
Na každém ze tří PCIe slotů na základní desce bylo spuštěno 8 testů – nVidia a Microsoft ML testy, každý ve float32, float16 a integer. Poté bandwidth test a Time Spy ve 3DMarku. Bylo sledováno vytížení GPU a její teplota, protože např. při prvním běhu Microsoft ML test využíval pouze CPU (po restartu systému již správně GPU).
Výsledky
PCIe gen4x16 vs. gen4x4 vs. gen3x2
Na grafu vidíme velký skok mezi x16 a x4 rychlostí, mezi gen4x4 a gen3x2 již takový skok není. Windows ML nemá velký rozdíl mezi x16 a x4 rychlostí, je to nejspíše způsobeno tím, že při výpočtech se značně využívá také procesor, u TensorRT se využívá vesměs jen GPU.

PCIe propustnost
Zde vidíme rozdíly dle předpokladů, u PCIe gen4x16 jsme na této (nepřetaktované) grafické kartě téměř dosáhli maximální možné propustnosti sběrnice (19% do maximální teoretické). Zajímavé je sledovat, že režie pro protokol, opravu chyb apod. jsou u dalších dvou téměř 25 % celkové datové propustnosti slotu.

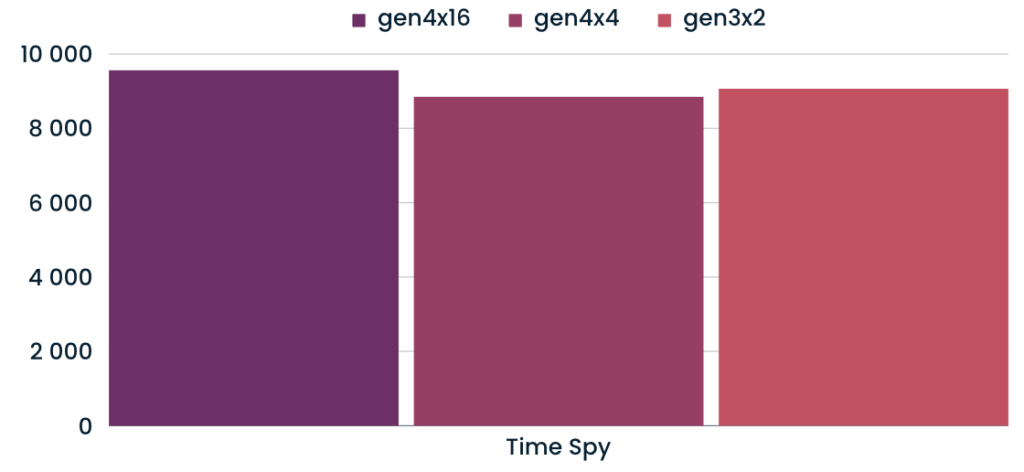
Time Spy
Testovali jsme také “herní” benchmark, abychom měli více dat k porovnání. Nejvíce nás zarazil o ~2% lepší výkon na gen3x2 slotu, než gen4x4 – nejdříve jsme mysleli, že to je chyba v měření, ale po několika pokusech byly výsledky podobné.
- gen4x4 -7,47% pod gen4x16
- gen3x2 -5.2% pod gen4x16
Závěr
Zajímavostí je využití PCIe gen4x16 slotu – téměř 27GB/s již u této grafické karty, která je spíše low-middle end. Maximální teoretická rychlost bez režií přenosu je 32GB/s, tím pádem se vyšší řady s přehledem dostanou až na hranu PCIe rychlosti. Záleží však na způsobu použití, AI modelu či velikosti cache grafické karty – cache může sběrnici ulehčit.
U PCIe gen4x4 a gen3x2 také krásně vidíme reálnou maximální rychlost PCIe sběrnic.
Dle dat můžeme odhadnout, že u gen4x8 slotu bude ponížení rychlosti zruba poloviční, než u gen4x4 slotu, tj. 11.5%.
Dle těchto výsledků je tedy na zvážení, zda si do workstation PC dávat např. desku Asus ProArt, která má 2x gen4x8 sloty a např. RTX 3090 v SLI nebo raději zakoupit RTX 4090 s podobnou cenou a vyšším výkonem (méně CUDA jader, ale více Tensor jader, více Cache, novější CUDA a další a tím pádem více TFLOPS). Další možností, ale dražší je pořízení serverové stanice např. s Threadripper/Xeon procesorem, který podporuje gen4 PCIe linky.
Kompletní tabulka dat s odkazy na benchmarky
| gen4x16 | gen4x4 | difference 4×16 vs 4×4 (%) | gen3x2 | difference 4×16 vs 3×2 (%) | |
| Windows ML float32 | 555 | 488 | 12 | 417 | 25 |
| nVidiaTensorRT float32 | 739 | 553 | 25 | 501 | 32 |
| nVidiaTensorRT float16 | 1608 | 1045 | 35 | 871 | 46 |
| Windows ML float16 | 1156 | 950 | 17 | 717 | 38 |
| nVidiaTensorRT integer | 2143 | 1297 | 39 | 1072 | 50 |
| Windows ML integer | 220 | 197 | 10 | 176 | 20 |
| PCI EXPRESS (GB/s) | 26,86 | 6,3 | 1,6 | ||
| Time Spy | 9561 | 8847 | 9064 | ||
| Average nVidia + Win ML comparison | -23% | -35% | |||
| Comparison Time Spy | -7,47% | -5.2% |